팀 프로젝트를 통해 서로 배우고 더 업그레이드 할 수 있는 기회 실무 기반 프로젝트로 스스로 레벨업하고 포트폴리오까지 완성할 수 있습니다! 혹시 이전 리뷰가 궁금하다면?
.png?type=w800)
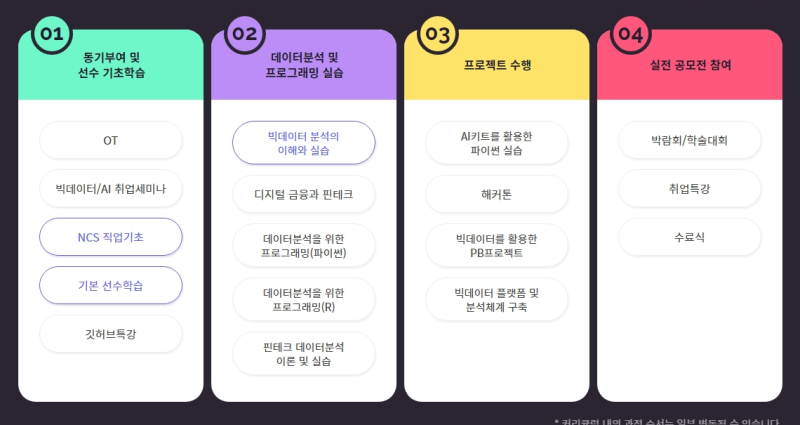
K-Digital Training PBL 기반 금융 빅데이터 분석가 4기 정00 수료생 프로젝트 2②/유비온디지털교육센터 금융 도메인 지식과 빅데이터 분석 기술을 바탕으로 실무 맞춤형 기술 교육과 멘토링 및 프로그램을 통해 협업… blog.naver.com
.png?type=w800)
K-Digital Training PBL 기반 금융 빅데이터 분석가 4기 정00 수료생 프로젝트 2②/유비온디지털교육센터 금융 도메인 지식과 빅데이터 분석 기술을 바탕으로 실무 맞춤형 기술 교육과 멘토링 및 프로그램을 통해 협업… blog.naver.com
인기글



.png?type=w800)
기획발표 후 본격적인 프로젝트 시작
.png?type=w800)
기획발표 후 본격적인 프로젝트 시작

실제로 이런 방식으로 기업 리스트를 제작하기도 했습니다.그다음 어려웠던 게 재무비율 결측치 처리였어요. Ts2000은 사업보고상의 분모분자 값에 따라 0 또는 빈칸에 나오는 데이터가 나옵니다. 또 별도의 재무제표로만 나오는 기업, 연결 기업에서만 나오는 기업의 각 가격 차이가 있기 때문에 이 모든 것을 고려해야 했습니다.

저 컬럼 안에 흰색 부분이 전부 0 또는 결측치였어요. 우리는 각 피쳐별 ts2000에서의 계산 공식을 찾고 그 공식에 맞게 직접 재무 데이터를 가져와 계산, 기존 비율과 비교하면서 확인하는 작업까지 진행했습니다. 이 재무비율 확인이 프로젝트 과정에서 가장 오래 걸렸어요. 이 부분에 이렇게까지 공을 들인 이유는 원본 데이터를 최대한 반영하기 위해서였습니다. 데이터 분석에서 가장 중요한 것은 결국 데이터니까요.
결측치 처리 후 EDA 진행

피쳐별 계산을 실시한 후에 나온 피쳐 내결측치입니다. 0은 실제 값이 반영될 수도 있기 때문에 결측값만 필터하고 시각화한 것인데 그렇게 만들기 위해 상당한 시간을 들였습니다.

다음으로 진행한 것은 데이터셋 구분입니다.이렇게 총 5개의 데이터 세트를 만들었습니다. 1) 경기국면을 고려하지 않은 10년 전체 데이터셋2) 구분기준1에 맞는 데이터셋3) 구분기준2에 맞는 데이터셋도 경기민감도에 따라 업종구분을 하고 더미변수까지 추가해 주었습니다. 그 후 EDA를 진행했습니다. 기본적인 머신러닝의 가정 성립을 모색하기 위해 정규성 검정을 실시했습니다.

재무비율은 데이터 특성상 정규성을 만족하기 어려웠습니다. 히스토그램과 같은 시각화 도구와 K-S 테스트나 샤피로위크 검정 등의 통계적 방법론을 적용하기도 했지만 모두 만족스러운 것은 아니었습니다. 아무래도 이상치가 많기 때문에 생기는 문제라고 생각해서 윈저라이징 및 스케일링을 진행했음에도 여전히 만족할 수 없었습니다. 그래서 이 부분은 데이터 수가 충분하다는 가정하에 진행하기로 했습니다.스케일링 방법도 가장 유의한 스케일링 방법을 찾기 위해 모델을 돌려 가장 결과가 좋은 방법을 사용하고자 했고, 유의한 변수 추출을 위한 피쳐 셀렉션도 가능한 다양한 방법론을 적용하여 공통 피쳐를 선정했습니다. 과정으로는 로짓 모델을 이용한 t검정, VIF를 확인하여 10이상이 값을 제거한 후(10을 초과하여도 유의한 변수는 제거하지 않았습니다.

Vif 값도 확인했고 위와 같이 sklearn에서 지원하는 3가지 method 내 6가지 방법의 결과를 종합하여 4번 이상 선택된 피쳐를 선정하도록 코드를 진행하였습니다. 이렇게 데이터 세트 및 스케일링 방법론별 피쳐 셀렉션을 돌려 그 결과를 정리했습니다.유비온 디지털 교육센터 K-Digital Training 금융 빅데이터 분석가 과정 교육비 전액 무료 훈련 수당 지급 취업 컨설팅 제공 기업 채용 추천 수업 교재 10권이미지를 클릭하면 이벤트 페이지로 이동합니다.이미지를 클릭하면 이벤트 페이지로 이동합니다.